
The StarCraft Multi-Agent Exploration Challenges
The StarCraft Multi-Agent Challenges requires agents to learn completion of multi-stage tasks and use of environmental factors without precise reward functions. The previous challenges (SMAC) recognized as a standard benchmark of Multi-Agent Reinforcement Learning are mainly concerned with ensuring that all agents cooperatively eliminate approaching adversaries only through fine manipulation with obvious reward functions. This challenge, on the other hand, is interested in the exploration capability of MARL algorithms to efficiently learn implicit multi-stage tasks and environmental factors as well as micro-control. This study covers both offensive and defensive scenarios. In the offensive scenarios, agents must learn to first find opponents and then eliminate them. The defensive scenarios require agents to use topographic features. For example, agents need to position themselves behind protective structures to make it harder for enemies to attack. We investigate MARL algorithms under SMAC-Exp and observe that recent approaches work well in similar settings to the previous challenges, but misbehave in offensive scenarios. Additionally, we observe that an enhanced exploration approach has a positive effect on performance but is not able to completely solve all scenarios. This study proposes a new axis of future research.
 |
 |
|---|---|
| SMAC-Exp_Offense | SMAC-Exp_Defense |
Paper and Source Codes
Here is the Paper and Code for the benchmarks and implemented baselines.
General Description of SMAC-Exp
This challenge offers advanced environmental factors such as destructible structures that can be used to conceal enemies and terrain features, such as a hill, that may be used to mitigate damages. Also, we newly introduce offensive scenarios that demand sequential completion of multi-stage tasks requiring finding adversaries initially and then eliminating them. Like in SMAC, both defensive and offensive scenarios in SMAC-Exp employ the reward function proportional to the number of enemies removed.
Comparison between SMAC and SMAC-Exp
| Main Issues | SMAC | SMAC-Exp |
|---|---|---|
| Agents micro-control | O | O |
| Multi-stage tasks | ▵ | O |
| Environmental factors | ▵ | O |
List of environmental factors and multi-stage tasks for both SMAC and SMAC-Exp
In SMAC, some difficult scenarios, such as 2c_vs_64zg and corridor, require agents to indirectly learn environmental factors, such as exploiting different levels of terrains or discover multi-stage tasks like avoiding rushing enemies first and then eliminating individuals without a specific reward for them. However, those scenarios do not allow quantitative assessment of the algorithm’s exploration capabilities, as they do not accurately reflect the difficulty of the task, which depends on the complexity of multi-stage tasks and the significance of environmental factors.
To address this issue, we propose a new class of the StarCraft Multi-Agent Exploration Challenges that encompasses advanced and sophisticated multi-stage tasks, and involves environmental factors agents must learn to accomplish, as seen in the table as follows.
• SMAC
| 2c_vs_64zg | Corridor | |
|---|---|---|
| Environmental factors | Different levels of the terrain | Limited sight range of enemies |
| Multi-stage tasks | - | Avoid enemies first, eliminate individually |
• SMAC-Exp
| Defense | Offese | |
|---|---|---|
| Environmental factors | Destroy obstacles hiding enemies | Approach enemies strategically Discover a detour Destory moving impediments |
| Multi-stage tasks | - | Identify where enemies place, then exterminate enemies |
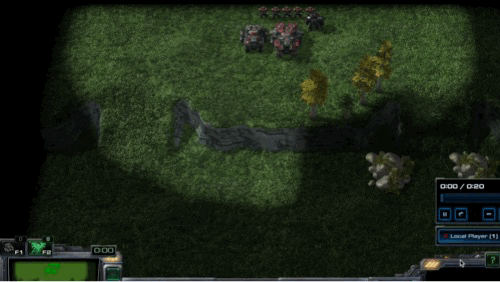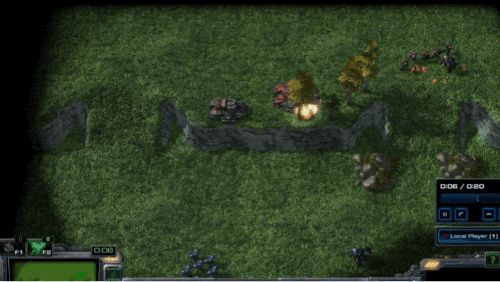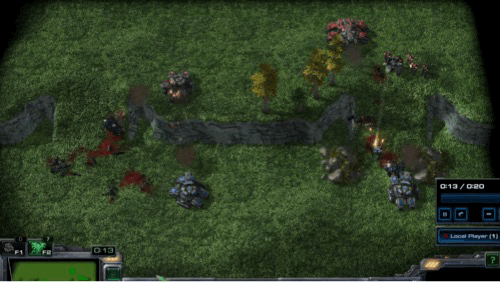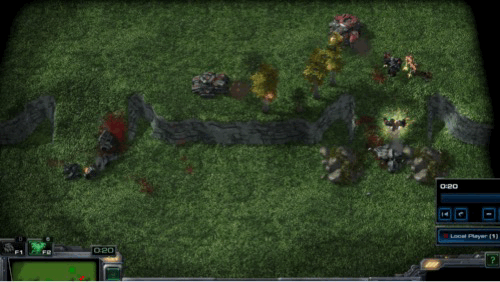
Defensive Scenarios in SMAC-Exp
- Graphical explanation of defensive scenarios

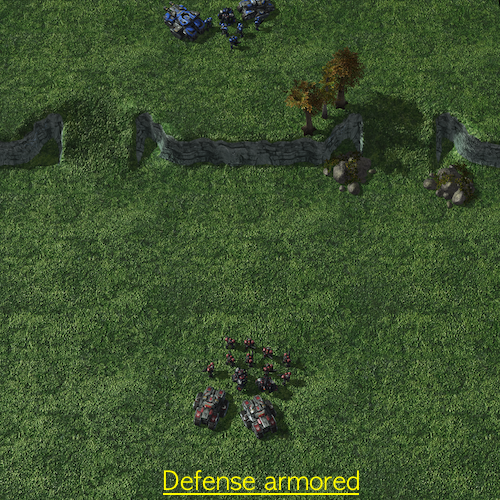

In defensive scenarios, we place allies on the hill and adversaries on the plain. We emphasize the importance of agents defeating adversaries utilizing topographical factors. The defensive scenarios in SMAC-Exp are almost identical to those in SMAC. However, our environment expands the exploration range of allies to scout for the direction of offense by allowing enemies to attack in several directions and adding topographical changes. We control the difficulties of the defensive settings as follows.
| Scenario | Supply difference | Opponents approach |
|---|---|---|
| Def_infantry | -2 | One-sided |
| Def_armored | -6 | Two-sided |
| Def_outnumbered | -9 | Two-sided |
Offensive Scenarios in SMAC-Exp
- Graphical explanation of offensive scenarios
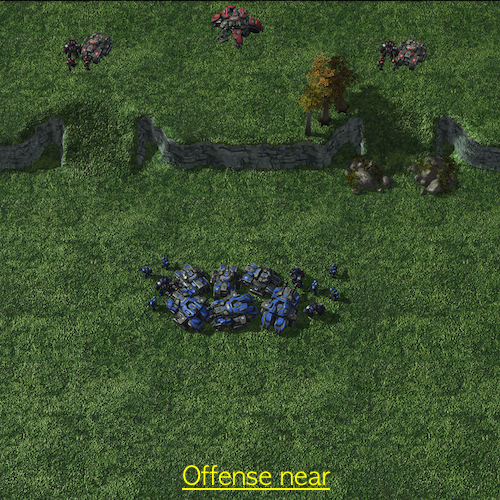
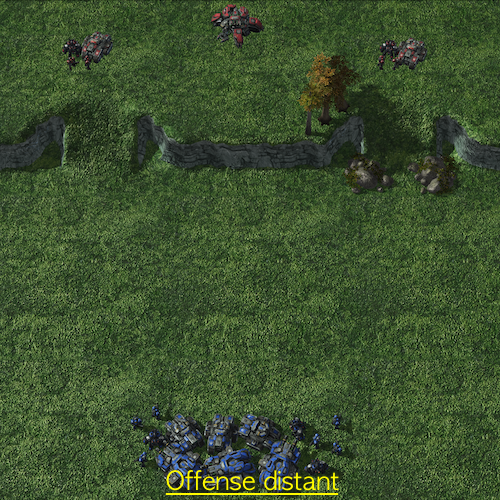
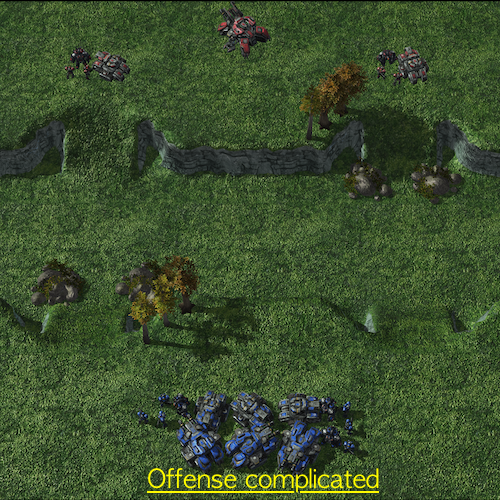
Offensive scenarios provide learning of multi-stage tasks without direct incentives in MARL challenges. We suggest that agents should accomplish goals incrementally, such as eliminating adversaries after locating them. To observe a clear multi-stage structure, we allocate thirteen supplies to the allies more than the enemies. Hence, as soon as enemies are located, the agents rapidly learn to destroy enemies. As detailed in the previous table, in SMAC-Exp, agents will not have a chance to get a reward if they do not encounter adversaries. This is because there are only three circumstances in which agents can get rewards: when agents defeat an adversary, kill an adversary, or inflict harm on an adversary. As a result, the main challenges necessitate not only micro-management, but also exploration to locate enemies.
| Scenario | Distance from opponents |
|---|---|
| Off_near | Near |
| Off_distance | Distant |
| Off_complicated | Complicated |
Challenging Scenarios in SMAC-Exp
- Graphical explanation of challenging scenarios
As a result, the main challenges necessitate not only micro-management, but also exploration to locate enemies. For instance, the agents learn to separate the allied troops, locate the enemies, and effectively use armored troops like a long-ranged siege Tank. We measure the exploration strategy of effectively finding the enemy through this scenario. In this study, we examine the efficiency with which MARL algorithms explore to identify enemies by altering distance from them. In addition, to create more challenging scenarios, we show how enemy formation affects difficulty.
| Scenario | Supply difference | Opponents formation |
|---|---|---|
| Off_hard | 0 | Spread |
| Off_superhard | 0 | Gather |
Benchmarks
To demonstrate the need for assessment of exploration capabilities, we choose eleven algorithms of MARL algorithms classified into three categories; policy gradient algorithms, typical value-based algorithms, and distributional value-based algorithms. First, as an initial study of the MARL domain, policy gradient algorithms such as COMA, MASAC, MADDPG are considered. The typical value-based algorithm including IQL, VDN, QMIX and QTRAN are chosen as baselines. Last but not least, we choose DIQL, DDN, DMIX and DRIMA as distributional value-based algorithms that recently reported high performance owing to the effective exploration of difficult scenarios in SMAC.
Defensive Sceanrios
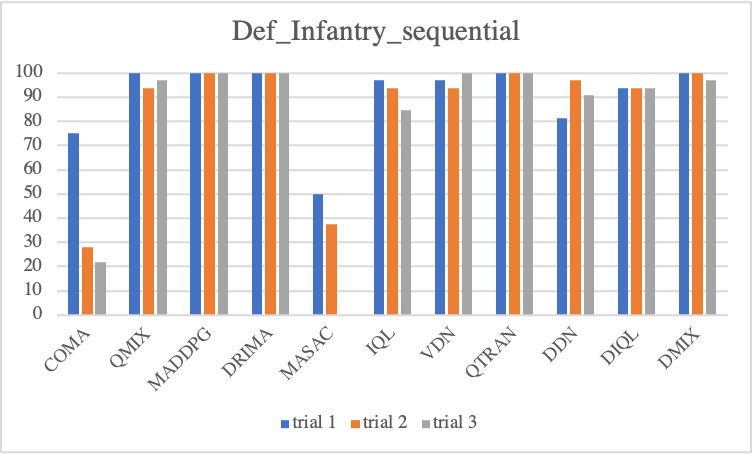
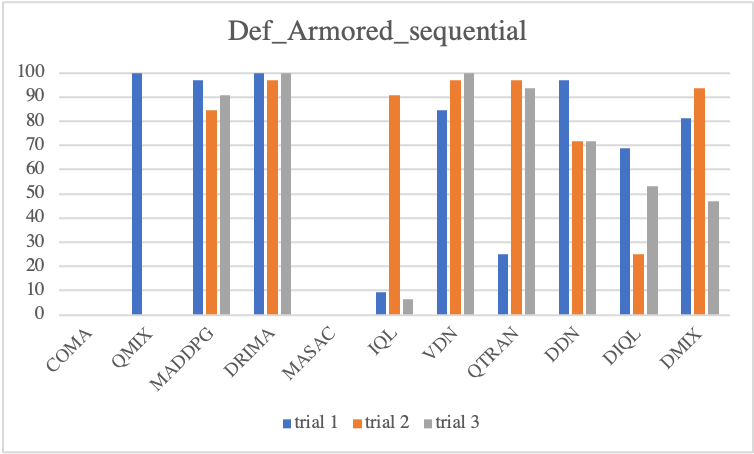
We first look into defensive scenario experiments on SMAC-Exp to test whether MARL algorithms not only adequately employ environmental factors but also learn micro-controls. In terms of algorithmic performance, we observe COMA and QMIX drastically degrade, but MADDPG gradually degrades. This fact reveals that MADDPG enables agents to effectively learn micro-control. However, among baselines, DRIMA achieves the highest score and retains performance even when the supply difference significantly increases.
• Sequential Episodic Buffer
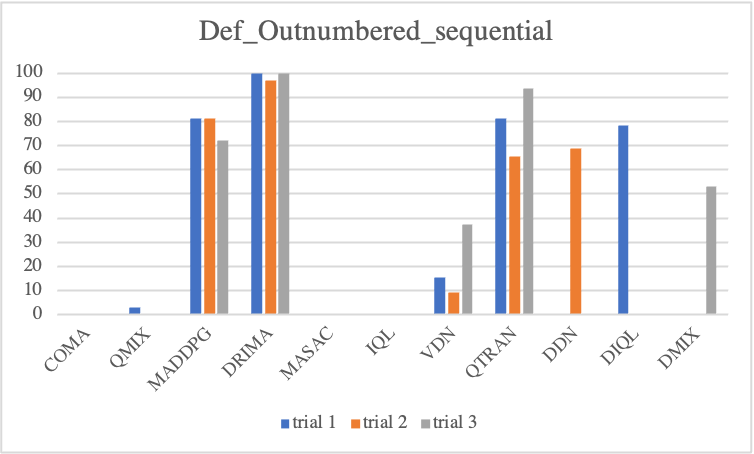
• Parallel Episodic Buffer
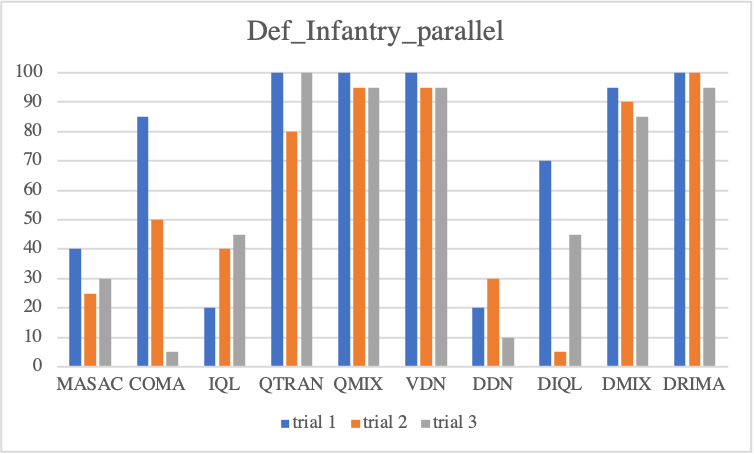
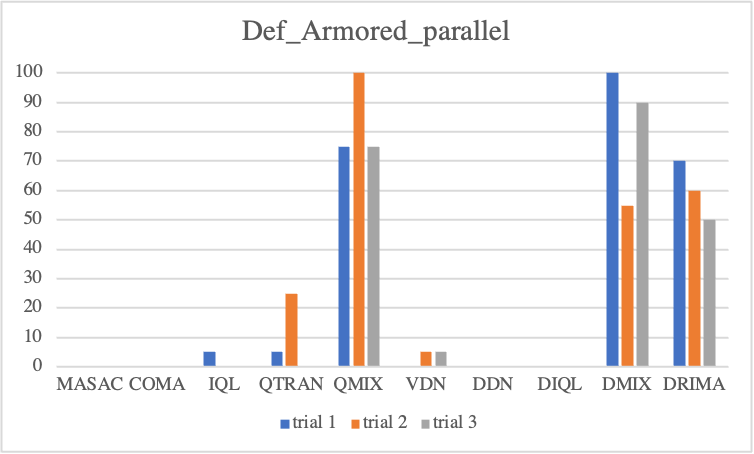
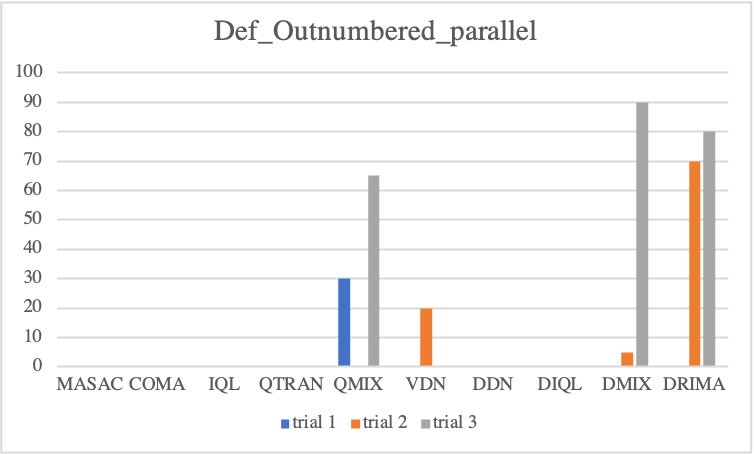
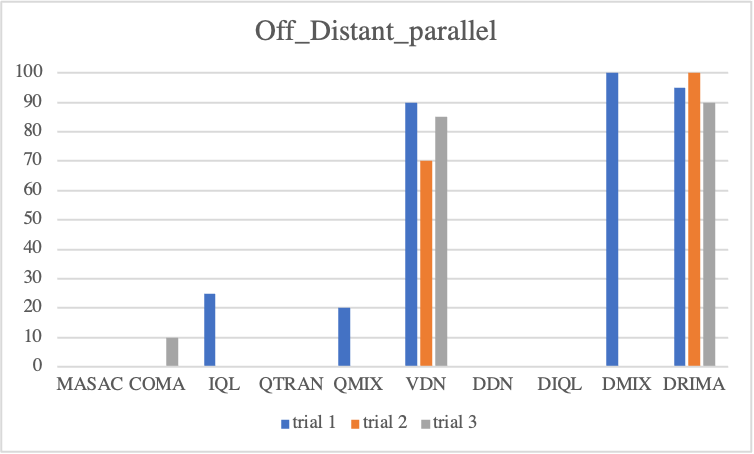
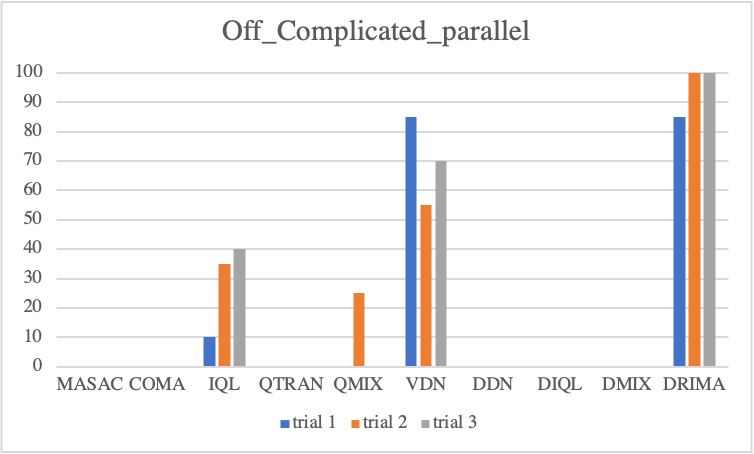
Offensive Sceanrios
Regarding to offensive scenarios, we notice considerable performance differences of each baseline. Overall, even if an algorithm attains high scores at a trial, with exception of DRIMA, it is not guaranteed to train reliably in other trials. As mentioned, offensive scenarios do not require as much high micro-control as defensive scenarios, instead, it is important to locate enemies without direct incentives, such that when agents find enemies during training, the win-rate metric immediately goes to a high score. However, the finding enemies during training is decided by random actions drawn by epsilon-greedy or probabilistic policy, resulting in considerable variance in test outcome. In contrast, we see a perfect convergence of DRIMA in all offensive scenarios by employing its efficient exploration.
• Sequential Episodic Buffer
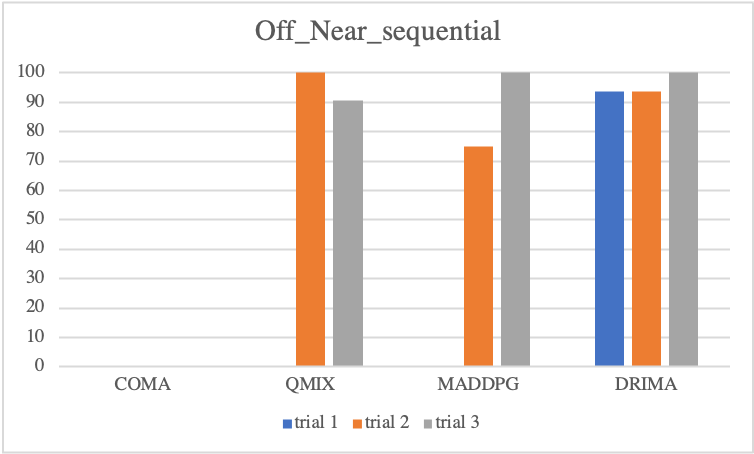
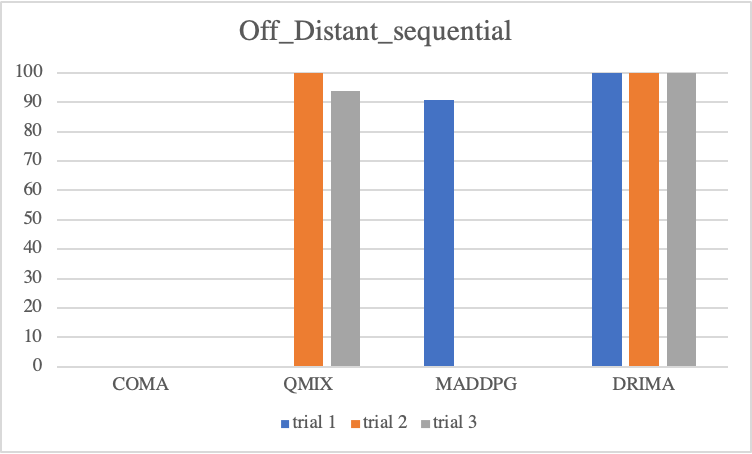
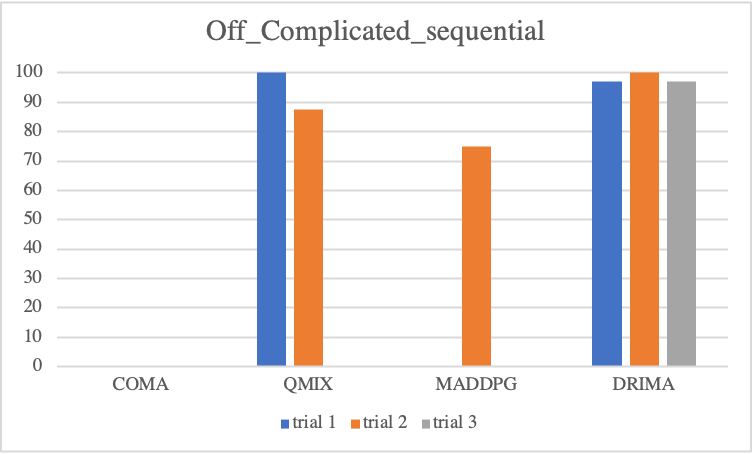
• Parallel Episodic Buffer
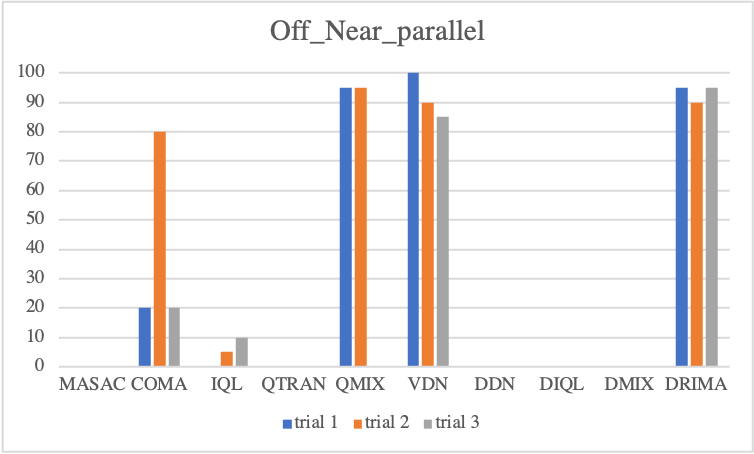
Challenging
To provide open-ended problems for the MARL domain, we suggest more challenging scenarios. In these scenarios, the agents are required to simultaneously learn completion of multi-stage tasks and micro-control during training. We argue that this scenario requires more sophisticated fine manipulation compared to other offensive scenarios. This is due to the fact that not only the strength of allies is identical to that of opponents, but also Gathered enables opponents to intensively strike allies at once. This indicates the necessity of more efficient exploration strategies for the completion of multi-stage tasks and micro-control.
• Sequential Episodic Buffer
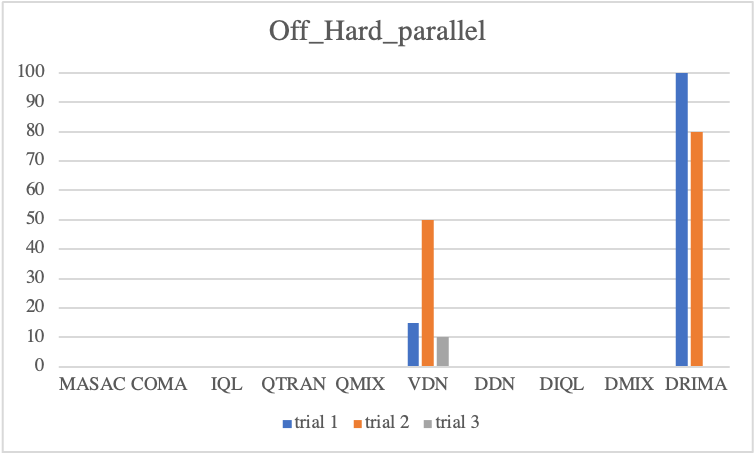
• Parallel Episodic Buffer
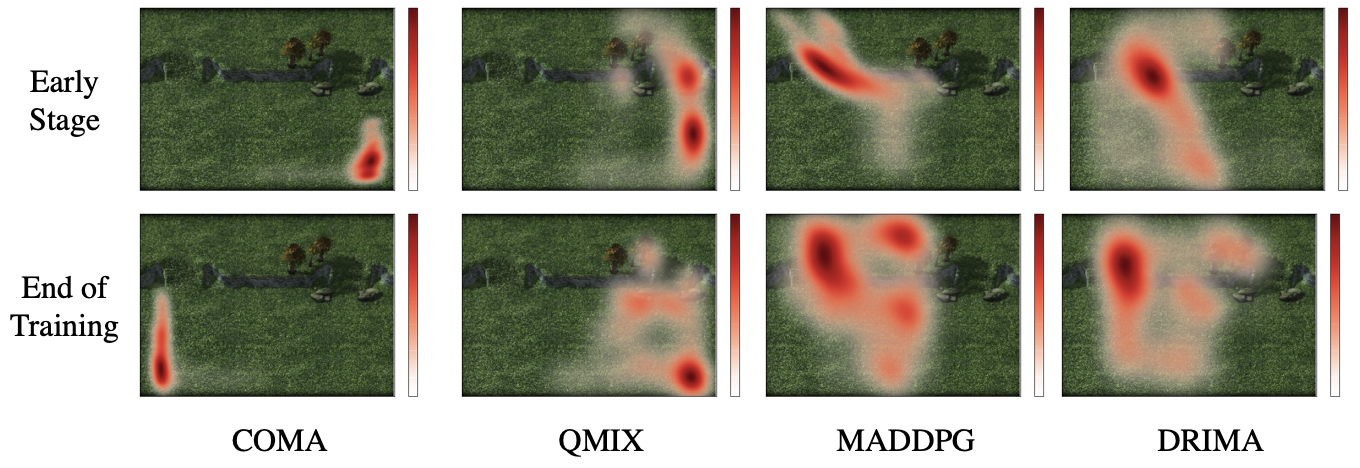
Ablation Study : Heatmaps of Agents Movement
Through the heat-maps of movements, we conduct qualitative analysis of each baseline. As illustrated in the heatmaps, at early stage of COMA only few agents find enemies. When it comes to end stage, agents do not face the opponents. Whereas although the early stage of DRIMA makes agents move around their starting points, its exploration capability makes agents get closer to enemies and finally confront them after training.




Future Direction
This study takes a look at multi-stage tasks in MARL. We mostly work on two-stage tasks. Two-stage tasks appear somewhat simplistic, but as early stage works, this work provides meaningful direction for exploration capability in MARL domains. We will develop MARL environments with multiple stage tasks in the future. We hope this work serves as a valuable benchmark to evaluate the exploration capabilities of MARL algorithms and give guidance for future research.
Acknowledgments
This work was conducted by Center for Applied Research in Artificial Intelligence (CARAI) grant funded by DAPA and ADD (UD190031RD).